
CSE253R: ML for Music
Instructor: Prof. Julian McAuley
This is a course I took especially to understand how ML gets applied to other domains like music. The course was taught by Prof. McAuley, and I noticed that the way he teaches concepts is starkly different from most other professors. The thing is, he understands what students want, he stresses the pain points where students struggle, and in a no-BS way, his class always focuses on the core elements students need to learn. He made sure not to bore us with the same ML content we’ve been learning in many other classes, but instead focused on the musical aspects of things.
The course delved into the following major topics:
- Data Structures for Music: This module covered the basics of sound and music theory, including sampling, digital and analog representations and conversions. I also learned key musical concepts such as pitch, notes, scales, and chord progressions.
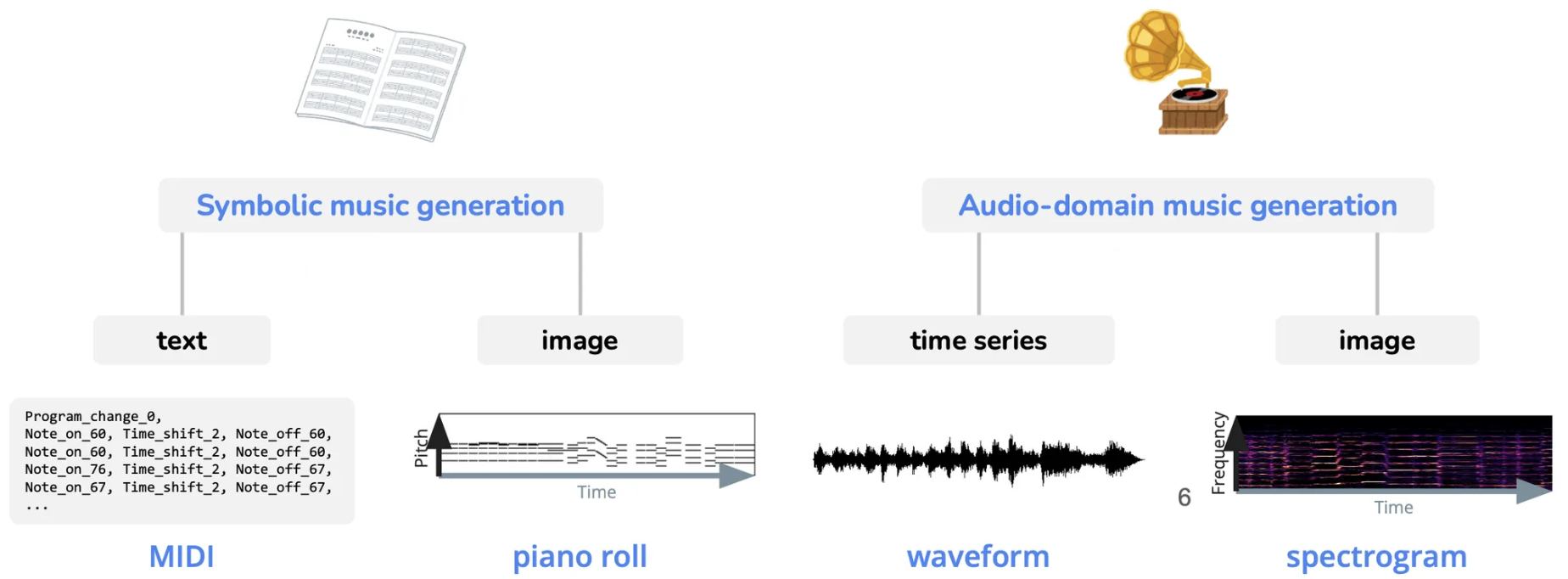
- Music Representations: This covered symbolic representations such as MIDI, sheet music, piano-roll, and ABC notation, as well as continuous representations using techniques like spectrograms, Mel-spectrograms, CQT, and MFCC. The module also overlapped with discussions on music information retrieval.
- Predictive Pipelines for Music: This module covered model architectures and pipelines for both symbolic and audio-domain representations of music, including 1D-CNNs, Music Transformers, CRNNs, and more. The professor also emphasized the importance of audio augmentation techniques.
- Music Generation: Prof. covered music generation in depth, including historical approaches to algorithmic composition such as Markov Chains and HMMs. The module also explored both symbolic (using LMs) and continuous (using GANs, VAEs, etc) music generation, both conditioned and unconditioned, along with their respective strengths and limitations.
- SOTA Audio Generation: This module covered latent-based modeling approaches, including latent waveform and spectrogram modeling. I also learned about prominent diffusion models and techniques for sampling and generation from them.
Few key-takeways to remember:
- While we conceptually treat audio as continuous, digital audio used in ML is actually discrete due to sampling and quantization. Continuous representations are closer to how humans perceive music, while symbolic representation is closer to the raw language of music.
- MC Issues: Low-order Markov chains produce strange, unmusical compositions that wander aimlessly. No memory. High-order chains essentially “rehash” musical segments from the corpus, and are also computationally expensive to train.
- Language models don’t map to music that naturally: it's not easy to deal with simultaneous or overlapping events + musical events have significant amounts of associated metadata (instrumentation, dynamics, phrasing, etc.). With music the tokenization is much more complex!
- CNNs are reusable pattern detectors and are invariant to shifts. They can also be used in music extensively. In audio we care about repeated musical patterns and invariance to pitch, timing and tempo. We can use CNNs for both symbolic (piano-rolls) and audio-domain (spectrograms) representations of music.
- Audio Augmentation can include techniques like random cropping (time), frequency filter, delay, reverberation, etc. They change the acoustic qualities of the piece, but shouldn’t change its label.
The homeworks and assignments were comprehensive and offered hands-on experience in applying ML to real problems in the musical domain. These included tasks like spectrogram construction and classification, symbolic music generation using Markov chains, and more. For me, the most rigorous and rewarding part of the course was a leaderboard based competition. It involved challenging tasks such as composer classification, multilabel music tagging, and next-sequence prediction. I spent five straight days working on this assignment, and it was totally worth it. Even though I performed well in only a few of the tasks, the learning experience was immense.
For Assignment 2, we were tasked with generating high-quality music. I worked on unconditioned symbolic music generation. I used a simple GAN architecture to produce the following symbolic music piece (converted to mp3 from midi):
Spring 2025