
CSE255: Data Mining and Analytics
Instructor: Prof. Yoav Freund
This course was highly valuable from a practical standpoint, offering insights into core concepts that underpin real-world data science and analytics in corporate environments. It helped me better understand and appreciate several subtle and seemingly simple ideas in data science that are often overlooked. Prof. Yoav Freund, who is notably one of the authors of the AdaBoost algorithm, has made significant contributions to the field. Learning from him and hearing his insights on several key topics gave me a fresh perspective on ideas that are otherwise considered routine in data science.
The course delved into the following major topics:
- Throughput vs. latency: Learned that the primary bottleneck in big data processing is often data movement, not computation. The concepts of latency and throughput lie at the heart of understanding and optimizing big data systems. Also learned in depth about caching, locality of storage accesses and the memory hierarchy.
- Distributed Computing: Learned the fundamentals of distributed computing through frameworks like Hadoop, including concepts like chunking in HDFS/GFS and their properties. Also studied Hadoop MapReduce and how it compares to in-memory data processing frameworks like Spark.
- Spark: Gained a deep understanding of Spark’s architecture and its spatial software organization, including key components such as the Driver, Cluster Manager, Workers, and Executors.
- RDD (Resilient Distributed Datasets): Learned about the core Spark data structure, RDDs, which enable distributed and in-memory processing, along with key properties like immutability, fault tolerance, and lineage.
- PCA: Learned about eigenvectors and PCA in great depth and associated metric like the percent variance explained and the importance of such metrics.
- K-means: Prof talked about the theoretical properties of k-means algorithm in a great depth. He also talked about different initialisation techniques, how to measure cluster stability, and how sparks "|| k-means" parallelises the k-means algorithm.
- Boosting: Learned about weak learners, decision trees, bagging and boosting algorithms. Prof explained his work on Adaboost and the idea of margins. He discussed many theoretical properties of boosting algorithms and talked about some other variants of boostings like brownboost, logitboost, etc.
- Latency: total time to process one unit from start to end. Throughput: number of units processed in one minute. Is Throughput = 1 / Latency? Not necessarily!.
- Transmitting TB of data through the internet is slow and expensive. Sending a physical disk through FedEx is cheap and high bandwidth.
- Heavy Tail Distributions The probability of outliers is much much higher than the probability given by the normal distribution with the same mean and variance. This phenomenon is common in memory hierarchy. It is a result of using memory caches. The average and std of the latency are dominated by the cache hits, but the rare cache misses result in the long tail.
- Achieving locality by being oblivious to order: To optimize performance, we want both sequential data access (for cache efficiency) and parallel processing (for multi-core scalability). Frameworks like MapReduce or Spark enable this by abstracting away computation order, allowing the system to determine the most efficient execution plan.
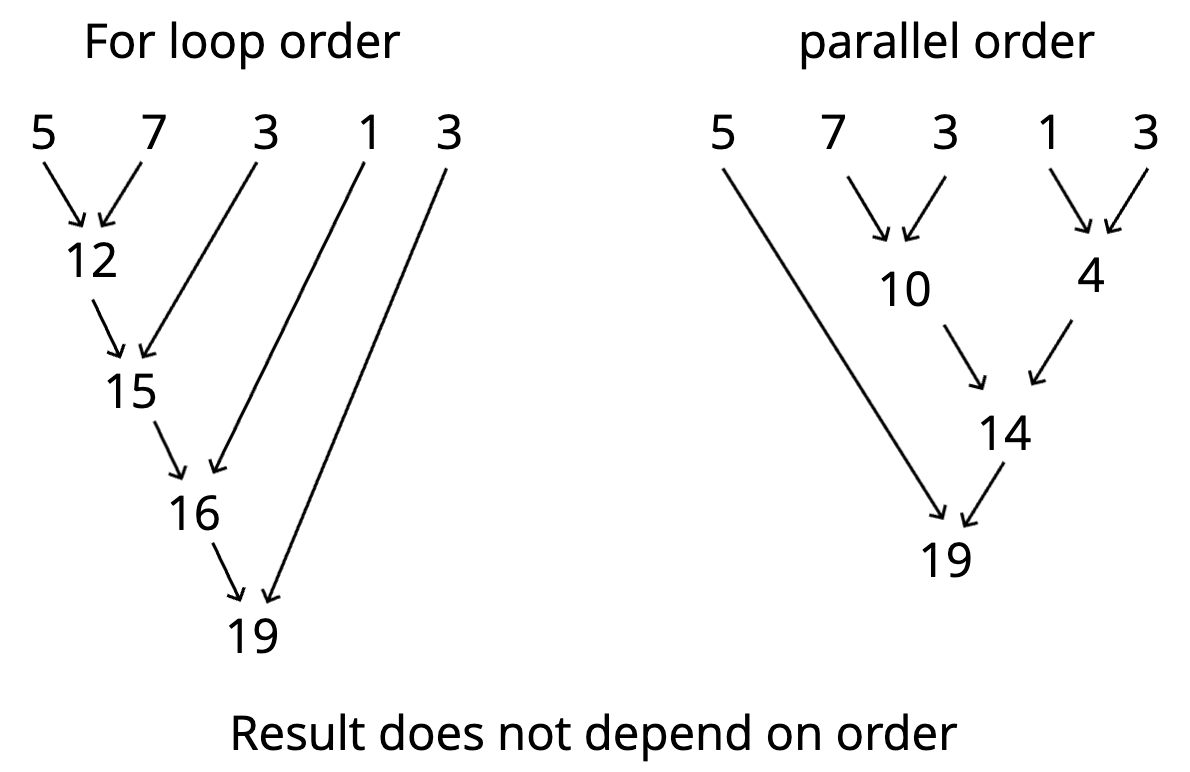
- Busy evaluation computes and stores all intermediate results, requiring multiple passes over the data. Lazy evaluation delays computation until needed, avoiding intermediate storage and enabling a single, efficient pass.
- Repartitioning for Load Balancing: When partitions are uneven, some workers may be idle while others are overloaded. This imbalance can worsen over time, especially if empty partitions persist. Repartitioning redistributes data evenly across workers to improve parallelism. A common way to do this is using .partitionBy(k) to assign a new key-based partitioning.
- Two main ways to manipulate DataFrames: Imperative manipulation uses methods like .select and .groupby, where you specify both what result you want and how to compute it. This gives you control over operation order. Declarative manipulation (using SQL) focuses only on what result you want, this allows for better optimization, though SQL lacks some advanced analysis primitives like covariance.
- The curse of dimensionality: Most statistical methods break down at high dimensions K-means breaks down in high dimension. A way out: some high dimensional data has low intrinsic dimension
- Ambient dimension is the raw dimension given i.e the dimension of the space in which the data is defined. Intrinsic dimension measures how much is the variability of the data intrinsically. OR a dimension that captures the variability of the data. If the data has a linear structure: PCA gives the intrinsic dim.
- K-means:
- K-means improves RMSE at each step (it either decreases or stays the same). Step 1 is Cluster Assignment, associating each data point with a closer centroid cannot increase RMSE. Step 2 is Update Centroid, the point with minimal RMSE for a set of points is the mean of those points.
- K-means converges after a finite number of iterations because the number of different possible RMSE values is finite, as the number of possible associations of points to centers is finite.
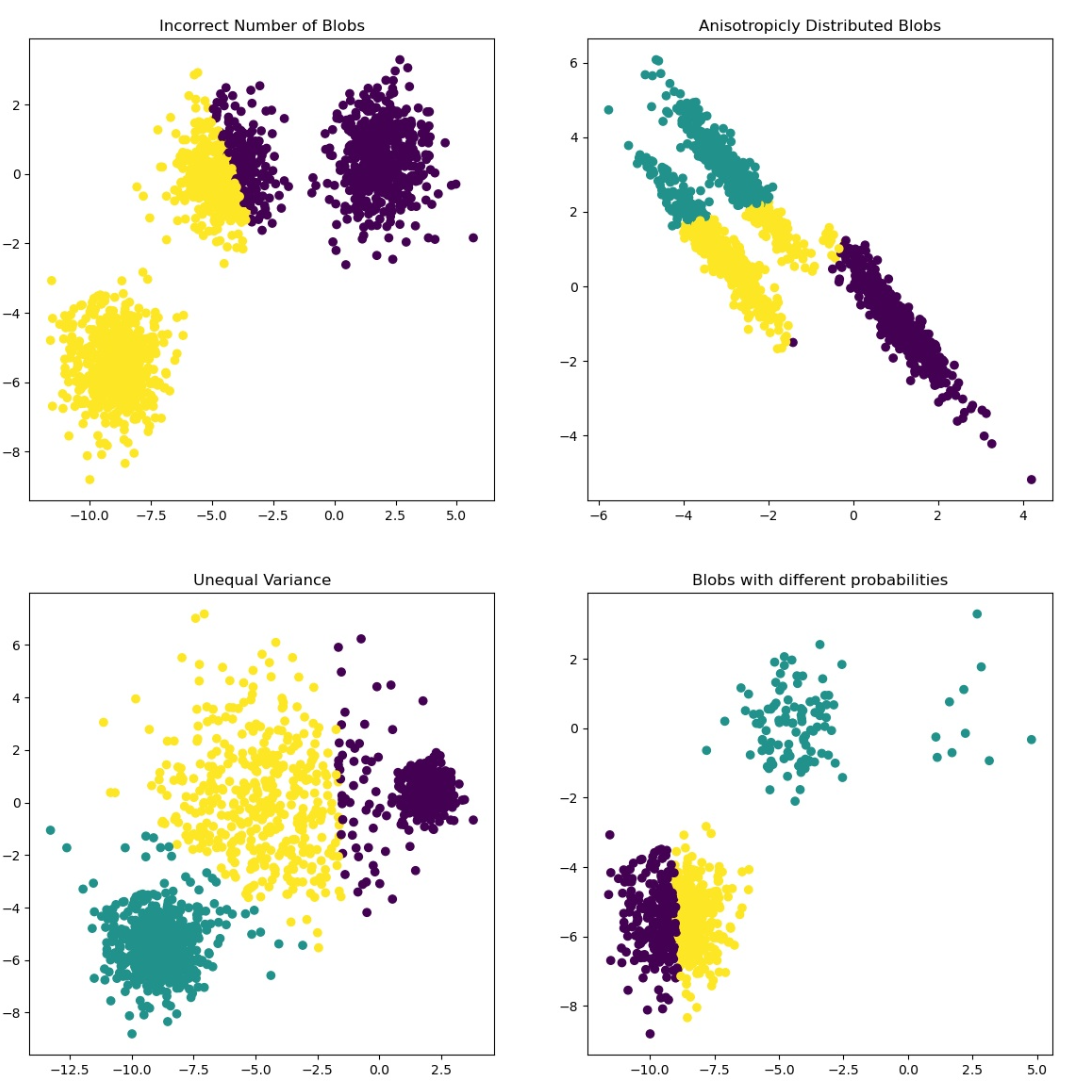
- Situations where K-means breaks down: Incorrect k value (#blobs), Wrong initialization, Anisotropically distributed blobs, etc.
- Boosting decision trees - Test error decreases even after training is reduced to 0. Why? because of margins: model pushes training examples further away from the decision boundary.
The HW assignments were pretty hands on (analysis of climate and weather pattherns of different states in the US) and were a major component of the course. Overall, while some components overlapped with other ML courses, it was valuable to gain a different perspective.
Spring 2025